『eStat』 기본 운용 및 데이터 조작
저자: 이정진 교수 (jjlee@ssu.ac.kr) [『eStat』 기본 운용 pdf]1. 『eStat』 기본 운영
1.1 『eStat』 들어가기 / 주화면 구성모니터에서 크롬 아이콘 |
|
|
『eStat』
|
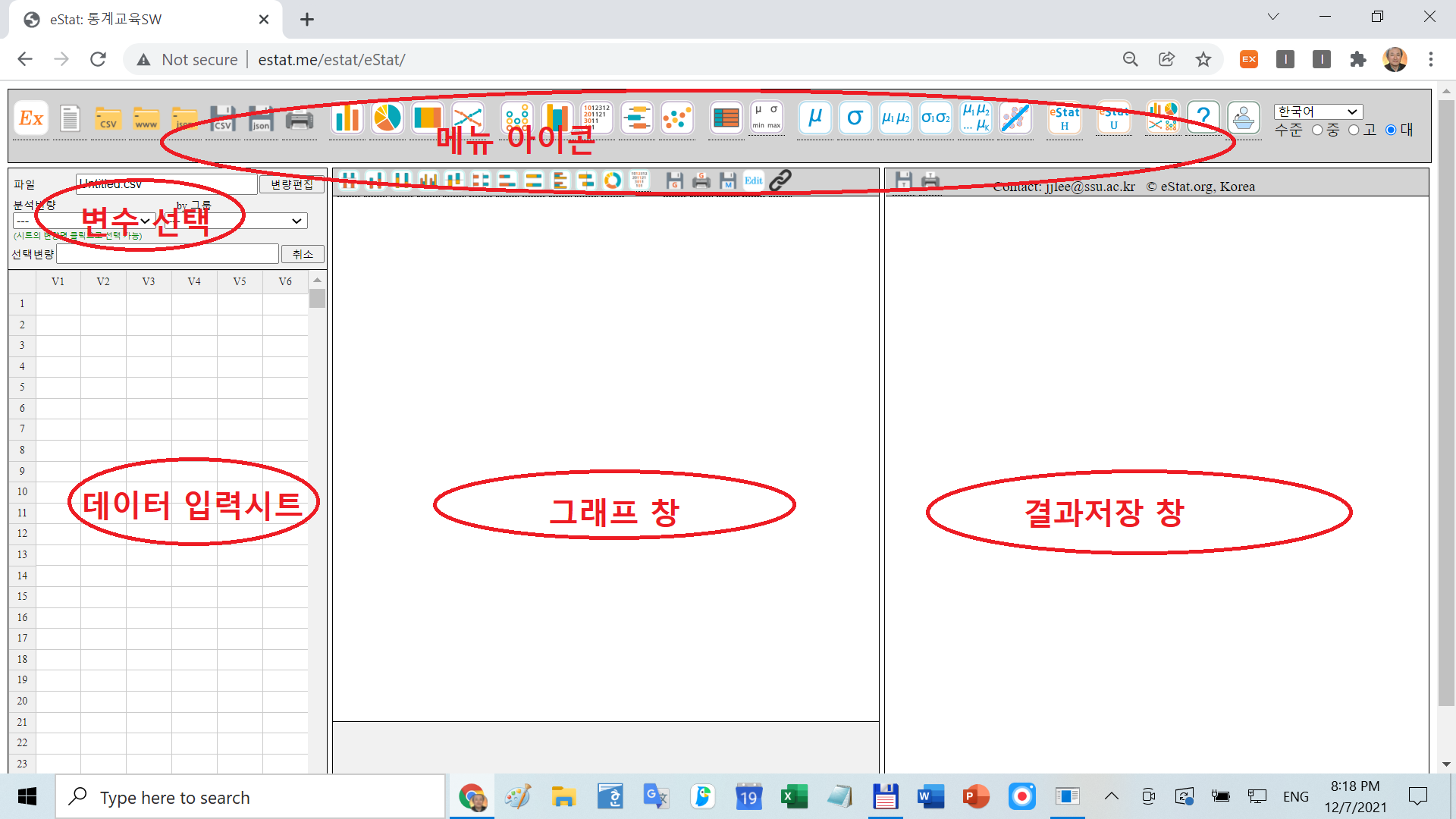
[그림 1.1] 『eStat』 주화면의 구성 |
|
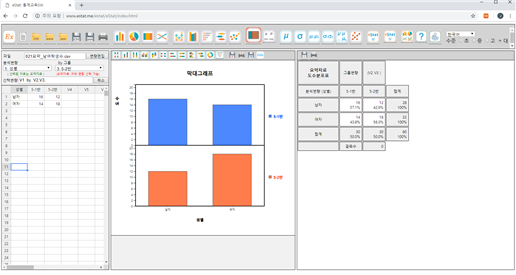
주화면은 크게 다섯 부분으로 나뉘어져 있다. 재알 윗부분에는 이 시스템의 메뉴에 해당하는 여러 가지 메뉴 아이콘들이 있고 그 밑에도 여러 가지 부메뉴 아아콘이 있다. 일반적인 소프트웨어에서 많이 사용하는 드롭다운 방식의 메뉴를 사용하지 않고 아이콘들을 펼쳐 놓은 것은 사용자들이 한 눈에 『eStat』에서 할 수 있는 작업을 보기 쉽게 하고, 모바일폰에서도 선택하기 쉽도혹 한 것이다. 주화면의 왼쪽은 데이터 입력을 위한 시트이다. 시트창 위에는 각 분석별로 필요한 ‘분석변량’이나 ‘그룹변량’을 선택하는 변수선택 대화상자가 있다. 주화면 가운데는 데이터 분석 결과를 그래프로 보여주는 그래프창, 오른쪽은 분석 결과를 표로 보여주거나 보관하는 결과저장창(로그(log)창)이 있다. [그림 1.2]는 간단한 데이터를 입력하여 그래프로 분석하고 결과를 결과저장창으로 보는 예이다.
[그림 1.2] 『eStat』의 데이터 분석 화면 예
고등학생이나 대학생의 효율적인 통계분석을 위해서는 여러 가지 메뉴가 더 있을 수 있어
아이콘 『eStatH』 |
|
|
『eStatH』
|

[그림 1.3] 『eStatH』 메뉴
|
|
『eStatU』
|
[그림 1.4] 『eStatU』 메뉴
|
1.2 데이터 만들기 / 저장하기 / 불러오기『eStat』에서 데이터 만들기주화면 좌측에 있는 시트에 데이터를 입력한다. 이 시트에서 행(row)은 관찰 대상, 열(column)은 변량을 나타낸다. 마우스로 1행 1열을 클릭하면 이 셀에 대한 행과 열이 다른 부분과 달리 진한 색으로 표시되고, 셀에는 직사각형 형태의 외곽선이 생기는데 이를 커서(cursor)라 한다. 이는 커서가 위치하여 있는 1행1열에 데이터를 입력받을 준비가 되어 있다는 것을 의미한다. 이 커서(cursor)는 화살표키 ← → ↑ ↓ 나 PgUp PgDn 키를 사용하면 셀에서 셀로 또는 페이지 단위로 커서를 이동시킬 수 있다.
[그림 1.5] 『eStat』 데이터 입력 시트
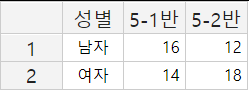
『eStat』에서 허용하는 데이터의 최대수는 9999개, 변량의 최대수는 20개이다. 데이터의 입력은 왼쪽 위의 1행 1열(관찰대상1, 변량1)서부터 데이터를 입력한 후, 아래 방향 화살표키(↓) (또는 Enter키)를 이용하여 커서를 밑(2행 1열)으로 이동시켜 다음 데이터를 입력한다. 같은 방법으로 화살표키(← → ↑ ↓ )를 이용하여 커서를 이동하면서 모든 데이터를 각 셀에 입력하면 된다. [그림 1.6]은 두 학급의 남 여 학생수를 입력한 예이다. 각 셀에는 데이터로 문자나 숫자를 입력할 수 있다.
[그림 1.6] 『eStat』 데이터 입력
막대, 원, 띠그래프는 문자 데이터을 이용해서 그래프를 그릴 수 있으나. 점그래프, 히스토그램, 줄기와 잎 그림은 반드시 숫자 데이터를 이용하여야 한다. 단 그룹변량은 문자 데이터를 이용할 수 있다. [그림 1.6]에서는 데이터가 시트 화면에 모두 보인다. 만일 데이터가 커서 시트 화면에 일부만 나타날 경우에는 PgUp, PgDn 키를 사용하여 위․아래로 한 화면씩 이동하여 볼 수 있고, Ctrl키와 화살표키(← → ↑ ↓)를 같이 눌러 데이터의 위/아래/왼쪽/오른쪽 끝으로 쉽게 이동할 수 있다.
|
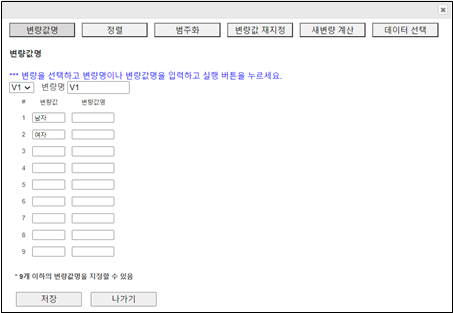
변량명 및 변량값명의 입력데이터의 입력이 끝난 후 『eStat』을 이용하여 데이터 처리를 하면 결과 출력은 변량이름으로 변량1(또는 V1), 변량2(또는 V2), 변량3(또는 V3) ... 라는 고유 이름이 나타난다. 이러한 고유 이름 대신 변량의 실제이름이나 그 변량 값에 대한 설명을 데이터처리 전에 입력하면 결과를 분석하기가 쉽다.[그림 1.6]에서 변량명의 입력은 데이터 입력 후에 ‘변량편집’ 버튼을 클릭하여 나타나는 [그림 1.7]의 대화상자에서 변량명 V1 대신 ‘성별’을 입력하고, 콤보박스에서 V2를 선택한 후 ‘5-1반’, V3를 선택한 후 ‘5-2반’을 입력하면 된다.
[그림 1.7] 변량편집의 변량값명 지정 대화상자
변량편집 대화상자를 이용하여 정렬(sorting), 범주화(categorize), 변량값 재지정(recode), 새변량 계산(compute), 데이터 선택(select if) 등을 할 수 있다.
|
데이터의 수정만일 한 셀에 입력된 데이터를 모두 수정하고 싶으면, 원하는 셀에 커서를 위치한 후 새 데이터를 입력하면 된다. 만일 한 셀에 입력된 데이터의 일부분만 수정하고 싶다면 원하는 셀을 마우스로 두 번 누른 후 화살표키(← →)를 이용하여 글자 사이를 이동하면서 수정을 하면 된다.
|
데이터의 저장시트에서의 데이터 입력은 컴퓨터의 주기억장치(main memory)를 이용하기 때문에 전원이 끊어지게 되면 이 기억장치에 들어 있는 내용은 모두 없어진다. 그러므로 데이터를 모두 입력한 후에는 이를 반드시 하드 디스크나 USB와 같은 보조 기억장치에 저장하여야 한다. 『eStat』에서는 파일이름 박스에 파일명을 입력하고 CSV 저장 아이콘
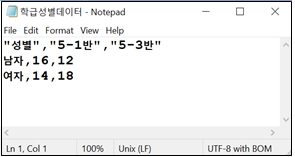
[그림 1.8] 메모장으로 열어본 csv 형식 파일
만일 변량값명까지 지정하였다면 JSON 저장 아이콘
|
저장된 파일 불러오기내 컴퓨터에 저장된 CSV 형식으로 저장된 파일은 CSV 불러오기 아이콘
다른 서버 컴퓨터에 저장된 CSV 형식으로 저장된 파일은 www 불러오기 아이콘
내 컴퓨터에 저장된 JSON 형식으로 저장된 파일은 JSON 불러오기 아이콘
|
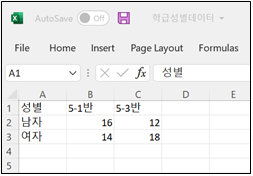
엑셀을 이용한 CSV 데이터 만들기엑셀을 이용하여 [그림 1.6]의 데이터를 [그림 1.9]와 같이 입력한 후 csv 형식으로 저장할 수 있다. 첫 행에 변수명을 그리고 2행 3행에 데이터를 입력한다.
[그림 1.9] 엑셀의 데이터 입력
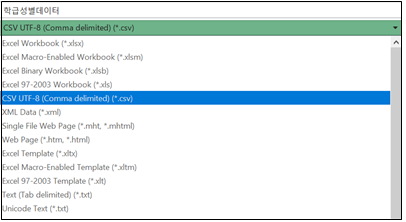
이 엑셀 파일을 저장할 때 (‘파일’ > ‘다른이름으로 저장‘) 여러 가지 선택사항이 있는데 [그림 1.10]과 같이 ’CSV UTF-8 (Comma delimited)’ 형식을 선택하여 저장한다.
[그림 1.10] 엑셀에서 csv 형식의 저장
|
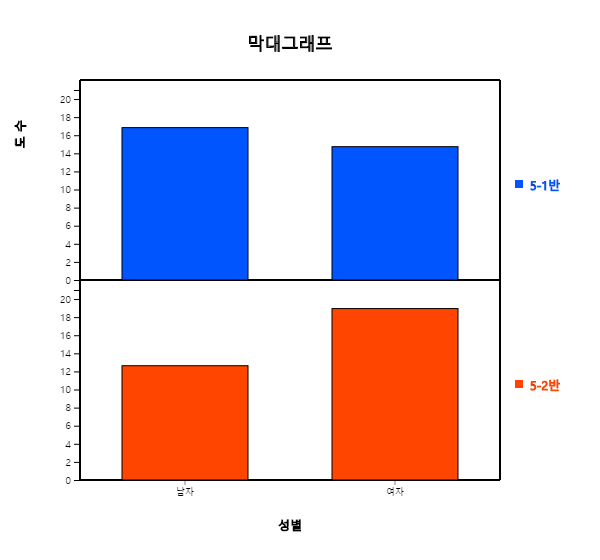
1.3 데이터 분석도수분포 데이터의 분석[그림 1.6]과 같은 데이터를 도수분포 데이터라 부른다. 시트에서 마우스로 변량명 ‘성별’과 ‘5-1반’ ‘5-2반’을 차례로 클릭하면 선택변량 박스에 ‘V1 V2 V3’ 가 나타나고 기본적으로 선택된 [그림 1.11]과 같은 남녀별 학생수에 대한 막대그래프 (
[그림 1.11] 5-1반과 5-2반의 남녀 학생수의 막대그래프
그래프의 제목은 원하는 내용으로 수정할 수 있다. 그래프창 위의 편집 아이콘 을 클릭하면 그래프 하단에 다음과 같은 편집 대화상자가 나타난다. 여기에서 주제목, y축제목, x축제목을 바꾼 후 ‘수정’ 버튼을 클릭한다.
[그림 1.12] 그래프 제목 편집 대화상자
|

1.4 결과 저장, 인쇄 및 『eStat』 시스템 나오기결과 저장『eStat』에서 그래프창에 표시된 분석 결과를 저장하려면 그래프창 위의 저장 아이콘 와 같이 표시된다. 저장되는 위치는 컴퓨터 시스템에서 지정된 다운로드(download) 폴더이다.
이어서 다른 그래프를 저장하면 다운로드 폴더에 eStatGraph(1).png 등과 같이 괄호 안의 번호가 증가되면서 저장된다.
와 같이 표시된다. 저장되는 위치는 컴퓨터 시스템에서 지정된 다운로드(download) 폴더이다.
이어서 다른 그래프를 저장하면 다운로드 폴더에 eStatGraph(1).png 등과 같이 괄호 안의 번호가 증가되면서 저장된다.
그래프창의 결과는 필요시 오른쪽의 결과저장창으로 이동한 후 필요시 인쇄할 수 있다.
그래프창 위의 이동 아이콘
결과저장창에 있는 내용을 저장하려면 결과저장창 위의 저장 아이콘
|
 와 같이 표시된다. 저장되는 위치는
역시 컴퓨터 시스템에서 지정된 다운로드(download) 폴더이다. 저장된 html 파일은
MS Word나 아래아 한글에서 불러올 수 있다.
와 같이 표시된다. 저장되는 위치는
역시 컴퓨터 시스템에서 지정된 다운로드(download) 폴더이다. 저장된 html 파일은
MS Word나 아래아 한글에서 불러올 수 있다.
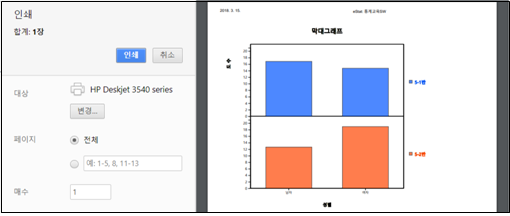
결과 인쇄그래프창의 결과를 인쇄하려면 그래프창 위의 인쇄 아이콘 을 클릭한다. 그러면 [그림 1.13]과 같은 윈도우에서 제공하는 인쇄를 위한 화면이 나타나고 여기서 ‘인쇄’ 버튼을 클릭하면 프린터에 그래프창 결과가 인쇄된다.
[그림 1.13] 그래프창의 인쇄
결과저장창의 결과를 인쇄하려면 결과저장창 위의 인쇄 아이콘
|
시스템 나오기eStat』시스템을 끝내려면 브라우저를 종료하면 된다. 즉, 브라우저 오른쪽 위의 ☒ 버튼을 클릭한다.
|
2. 『eStat』 데이터 조작
|
『eStat』 에는 일반적인 통계패키지와 같이 여러가지 데이터 조작기능이 있다.버튼
[그림 1.15]
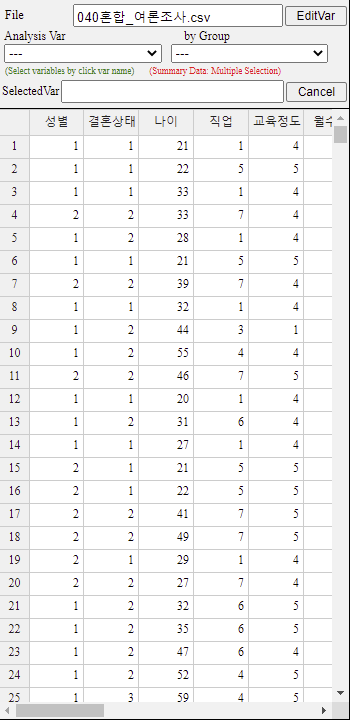
이 데이터는 40개의 행과 6열로 이루어져 있으며 변량명과 범주형 변량에 대한 변량값의 의미는 다음과 같다.
V1 성별 1:남자, 2:여자
|
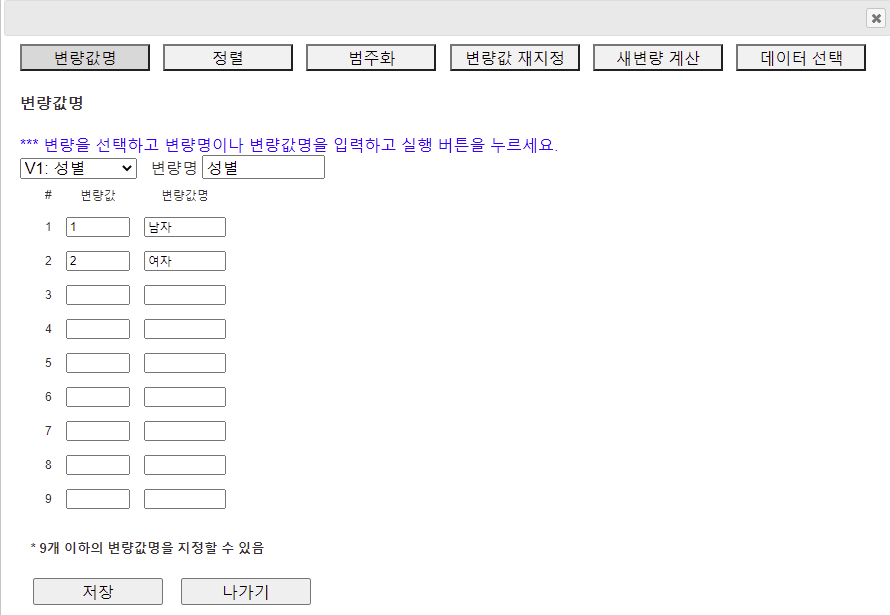
2.1 『변량명, 변량값명 (Value Label) 지정
[그림 1.16] 변량편집 대화상자
화면에는 V1:성별 변량이 선택되어 있고 변량값 1, 2가 보이는데 그 오른쪽에 변량값명을 그림처럼 '남자', '여자'를 입력하면 된다. 같은 방법으로 다른 범주형 변량을 선택하고 변량값명을 입력한다. 최대 9개까지의 범주화 변량값명을 입력할 수 있다.
입력이 끝난 후 [저장]버튼을 누른 후 [나가기] 버튼을 누르면 시스템이 변량값명을 기억한다. 하지만 이 변량값명을 파일에
저장하려면 json 형식으로 저장(
|
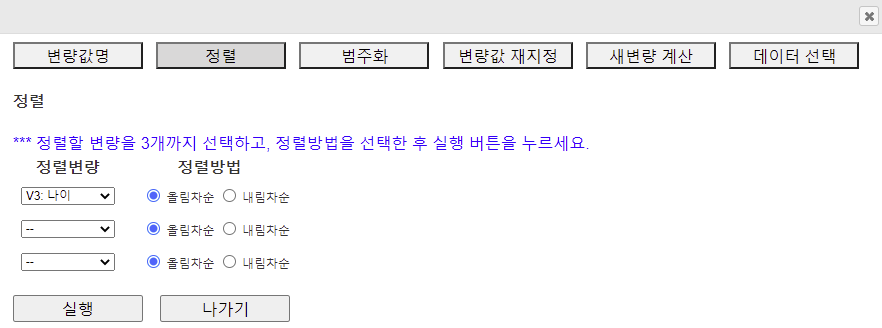
2.2 정렬 (Sorting)
[그림 1.17] 정렬 대화상자
여기에서 정렬변량을 선택하고 올림차순이나 내림차순 정렬방법을 선택한 후 [실행]버튼을 누르면 시트에 정렬된 데이터가 나타난다. 세 개까지의 정렬변량을 선택할 수 있는데 첫 째 변량이 정렬된 내에서 두번 째 변량이 정렬되고, 다시 첫 째와 둘째 변량을 정렬된 내에서 세번 째 변량이 정렬된다. 나이 올림차순으로 정렬된 데이터가 [그림 1.18]과 같다.
[그림 1.18] 나이 올림차순으로 정렬된 데이터
|
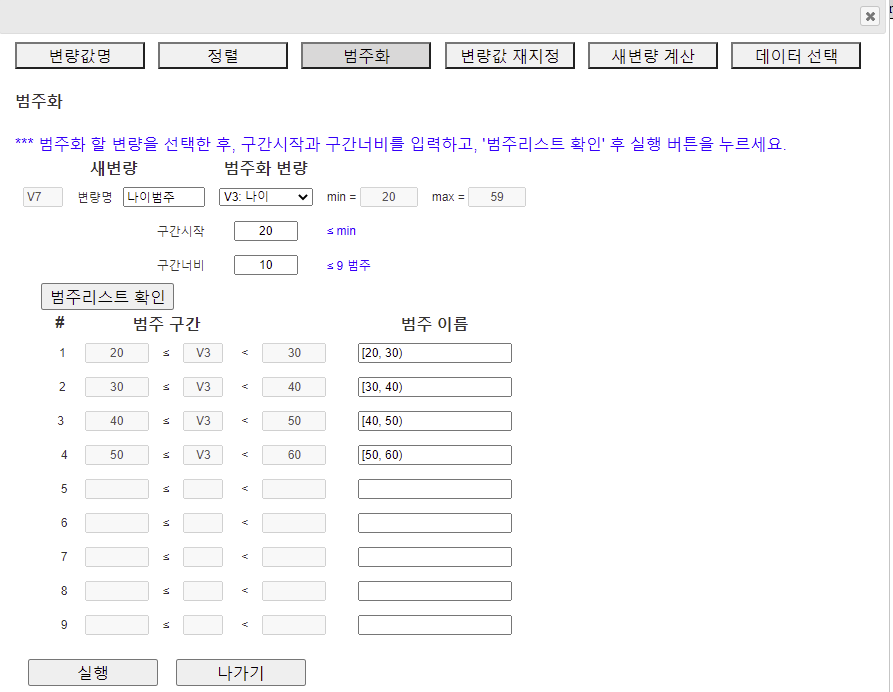
2.3 범주화 (Categorize)
[그림 1.19] 범주화 대화상자
새롭게 만들어지는 범주화 변량은 자동적으로 시트의 제일 오른쪽에 위치한다. 이 예의 경우 6개의 변량이 있으므로 V7에 범주화 변량이 만들어 진다. 필요한 경우 새 변량명을 입력하고 (예: 나이범주) 여기에서 범주화 할 변량 변량을 선택한다. 여기서는 V3:나이를 선택하였는데 바로 오른쪽에 선택된 나이 변량의 최소값(min) 20과 최대값(max) 59가 보여진다. 이 정보를 이용하여 구간시작을 20, 구간너비를 10으로 입력한 후 [범주리스트 확인] 버튼을 누르면 생성되는 범주구간을 [그림 1.19]와 같이 관찰할 수 있다. 새로운 범주화 변량 V7 '나이범주' 데이터가 [그림 1.20]과 같다.
[그림 1.20] 생성된 나이 범주화 데이터
|
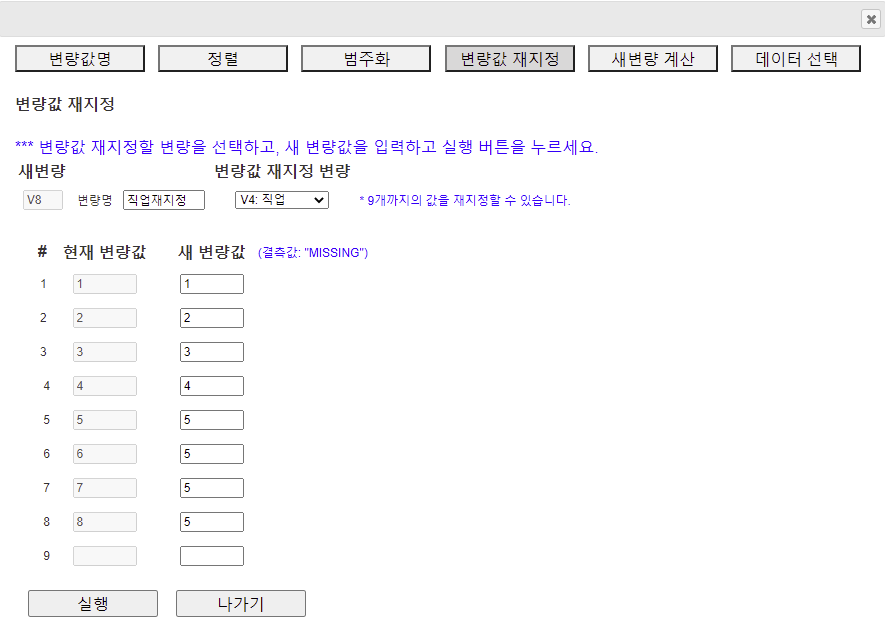
2.4 변량값 재지정 (Recode)
[그림 1.21] 변량값 재지정 대화상자
새롭게 만들어지는 범주화 변량은 자동적으로 시트의 제일 오른쪽에 위치한다. 이 예의 경우 현재 7개의 변량이 있으므로 V8에 새로운 변량값 재지정 변량이 만들어 진다. 필요한 경우 새 변량명을 입력하고 (예: 직업재지정) 여기에서 재지정 할 변량 변량을 선택한다. 여기서는 V4:직업을 선택하였는데 현재 변량값이 [그림 1.21] 왼쪽에 나타난다. 이 중에서 직업 6, 7, 8을 새로운 변량값으로 5를 지정하고 [실행] 버튼을 누른다. 새로운 범주화 변량 V8 '직업재지정' 데이터가 [그림 1.22]와 같다.
[그림 1.22] 변량값 재지정된 데이터
|
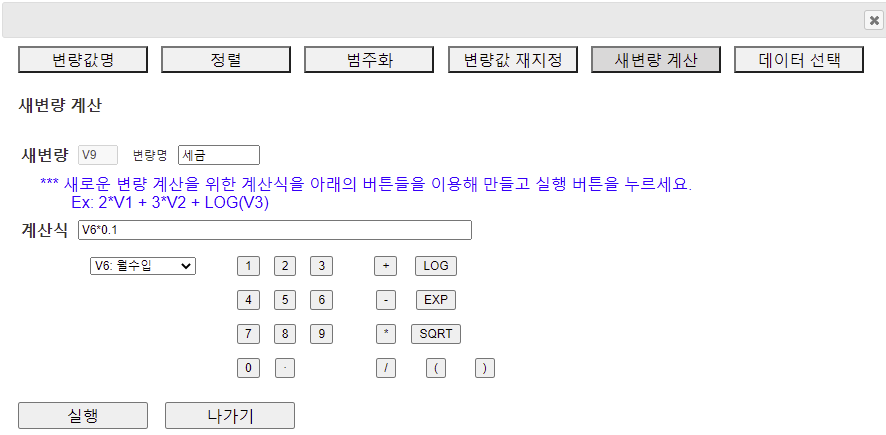
2.5 새변량 계산 (Compute)
[그림 1.23] 새변량 계산 대화상자
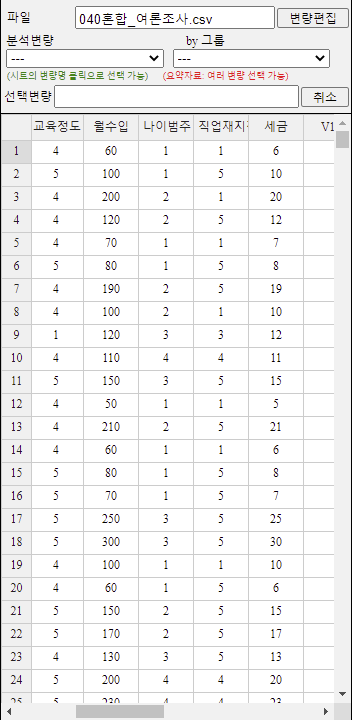
새롭게 만들어지는 계산 변량은 자동적으로 시트의 제일 오른쪽에 위치한다. 이 예의 경우 현재 8개의 변량이 있으므로 V9에 새로운 계산된 변량이 만들어 진다. 필요한 경우 새 변량명을 입력하고 (예: 세금) '계산식'을 그 밑의 변수나 숫자, 산술연산자(+, -, *, /), 함수(LOG, EXP, SQRT)를 이용하여 완성한다. 여기서는 V6:월수입에 0.1을 곱합 계산식 V6*0.1을 만들어 [실행] 버튼을 누른다. 계산된 변량 V9 '세금' 데이터가 [그림 1.24]와 같다.
[그림 1.24] 새롭게 계산된 변량 데이터
|
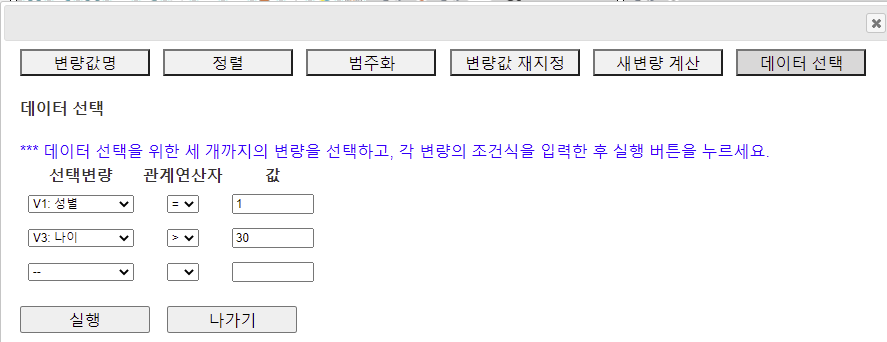
2.6 데이터 선택 (Select If)
[그림 1.25] 데이터 선택 대화상자
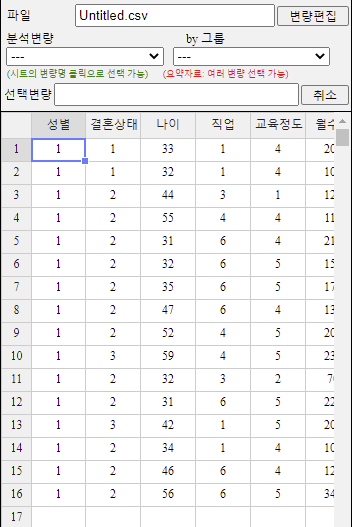
변량을 선택하고 관계연산자(=, <, ≤, >, ≥, ≠)를 선택한 후 값을 입력하여 조건식을 완성한다. 세 변량까지의 조건식을 만들 수 있다. 여기서는 V1:성별에서 남자를 선택하고 V3:나이에서 30세 이상의 조건식을 만든 후 [실행] 버튼을 누른다. 남자이면서 30세 이상으로 선택된 데이터가 [그림 1.26]과 같다.
[그림 1.26] 남자이면서 30세 이상으로 선택된 데이터
|